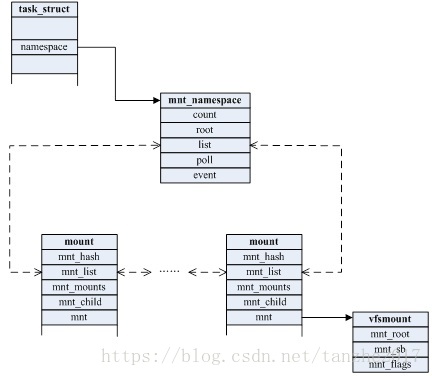
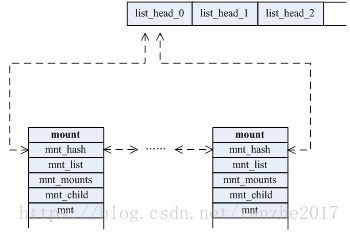
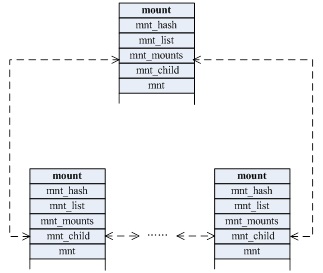
每个 mount namespace 都有一份自己的挂载点列表。当我们使用 clone 函数或 unshare 函数并传入 CLONE_NEWNS 标志创建新的 mount namespace 时, 新 mount namespace 中的挂载点其实是从调用者所在的 mount namespace 中拷贝的。但是在新的 mount namespace 创建之后,这两个 mount namespace 及其挂载点就基本上没啥关系了(除了 shared subtree 的情况),两个 mount namespace 是相互隔离的。
structmnt_namespace { atomic_t count; structns_commonns; structmount * root; structlist_headlist; structuser_namespace *user_ns; structucounts *ucounts; u64 seq; /* Sequence number to prevent loops */ wait_queue_head_t poll; u64 event; unsignedint mounts; /* # of mounts in the namespace */ unsignedint pending_mounts; } __randomize_layout;
structmount { structhlist_nodemnt_hash; structmount *mnt_parent; structdentry *mnt_mountpoint; structvfsmountmnt; union { structrcu_headmnt_rcu; structllist_nodemnt_llist; }; #ifdef CONFIG_SMP structmnt_pcp __percpu *mnt_pcp; #else int mnt_count; int mnt_writers; #endif structlist_headmnt_mounts;/* list of children, anchored here */ structlist_headmnt_child;/* and going through their mnt_child */ structlist_headmnt_instance;/* mount instance on sb->s_mounts */ constchar *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */ structlist_headmnt_list; structlist_headmnt_expire;/* link in fs-specific expiry list */ structlist_headmnt_share;/* circular list of shared mounts */ structlist_headmnt_slave_list;/* list of slave mounts */ structlist_headmnt_slave;/* slave list entry */ structmount *mnt_master;/* slave is on master->mnt_slave_list */ structmnt_namespace *mnt_ns;/* containing namespace */ structmountpoint *mnt_mp;/* where is it mounted */ union { structhlist_nodemnt_mp_list;/* list mounts with the same mountpoint */ structhlist_nodemnt_umount; }; structlist_headmnt_umounting;/* list entry for umount propagation */ #ifdef CONFIG_FSNOTIFY structfsnotify_mark_connector __rcu *mnt_fsnotify_marks; __u32 mnt_fsnotify_mask; #endif int mnt_id; /* mount identifier */ int mnt_group_id; /* peer group identifier */ int mnt_expiry_mark; /* true if marked for expiry */ structhlist_headmnt_pins; structhlist_headmnt_stuck_children; } __randomize_layout;
0x03 命名空间
Mount namespaces (Linux2.4.19) 隔离一组进程的文件系统层次。在使用了新 Mount Namespaces 后,mount() 和 umount() 就会在新的文件系统层次上操作,而不是在全局(默认)文件系统层次上。