About Linux PID Namespace source code.
0x00 PID 框架设计
内核的大量数据结构被哈希表和链表链接起来,最主要的目的就是在于查找。可想而知一个好的框架,应该要考虑到检索速度,还有考虑功能的划分。在 PID 框架中,主要考虑以下几个因素:
- 如何通过 task_struct 快速找到对应的 pid
- 如何通过 pid 快速找到对应的 task_struct
- 如何快速的分配一个唯一的 pid
0x01 原始 PID 框架
1 | struct task_struct |
一个进程对应一个 pid ,可以通过 task_struct 轻松找到 pid 。但通过 pid 查找 task_struct 难以实现。
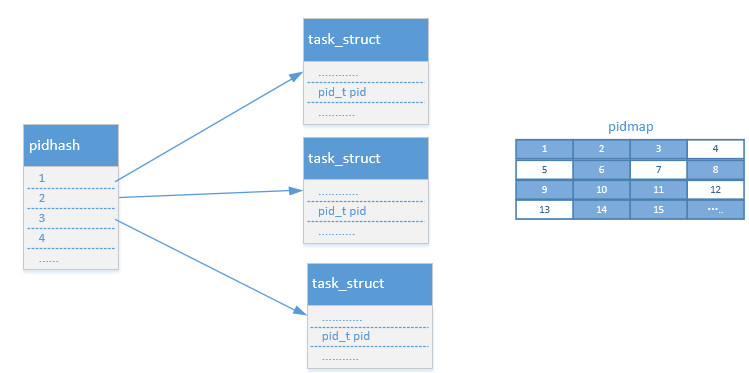
0x02 引入 hlist 和 pid 位图
1 | struct task_struct *pidhash[PIDHASH_SZ]; |
使用了 pid 位图,标记 pid 是否可用, pid 位图的方式更加节约内存。通过将每一位设置为 0 或者是 1 ,可以用来表示是否可用,第 1 位的 0 和 1 用来表示 pid 为 1 是否可用,以此类推。
0x03 引入 PID 类型
由于一个进程除了进程 pid ,还有进程组 pid 和会话 pid ,因此引入了 pid 类型:
1 | struct task_struct |
对于进程组 pid 来说,信号需要知道,通过这个 pid ,可以实现对一组进程进行控制,所以这个 pid 出现在了 signal 这个结构体中。无论是 session pid 还是 group pid 其实都不占用 pid 的资源,因为 session pid 是和领导进程组的组 pid 相同,而 group pid 则是和这个进程组中的领导进程的 pid 相同。
0x04 引入 PID 命名空间后的 PID 框架
随着内核不断的添加新的内核特性,尤其是 PID Namespace 机制的引入,使得 PID 存在命名空间的概念,并且命名空间还有层级的概念存在,高级别的可以被低级别的看到,这就导致高级别的进程有多个 PID 。
比如说在默认命名空间下,创建了一个新的命名空间,叫做 Level 1,默认命名空间这里称之为 Level 0,在 Level 1 中运行了一个进程,其在 Level 1 中的 pid 为 1。因为高级别的 pid namespace 需要被低级别的 pid namespace 所看见,所以这个进程在 Level 0 中会有另外一个 pid,假设为 xxx。套用上面说到的 pid 位图的概念,对于每一个 pid namespace 来说都应该有一个 pidmap,上文中提到的 Level 1 进程有两个 pid 一个是 1,另一个是 xxx,其中 pid 为 1 是在 Level 1 中的 pidmap 进行分配的,pid 为 xxx 则是在 Level 0 的 pidmap 中分配的。下图是整个 pid namespace 的一个框架:

引入了 PID 命名空间后,一个 pid 就不仅仅是一个数值那么简单了,还要包含这个 pid 所在的命名空间、父命名空间和命名空间多对应的 pidmap、命名空间的 pid 等等。因此内核对 pid 做了一个封装,封装成 struct pid:
1 | enum pid_type |
引入了 pid namespace 后,结构变得很复杂多了。进程如何和 struct pid 关联起来呢?内核为了统一管理 pid、进程组 pid 和会话 pid,将这三类 pid,进行了整合。现在 task_struct 要和三个 struct pid 关联,还要区分 struct pid 的类型。所以内核又引入了中间结构将 task_struct 和 pid 进行了 1 对 3 的关联。其结构如下:
1 | struct pid_link |
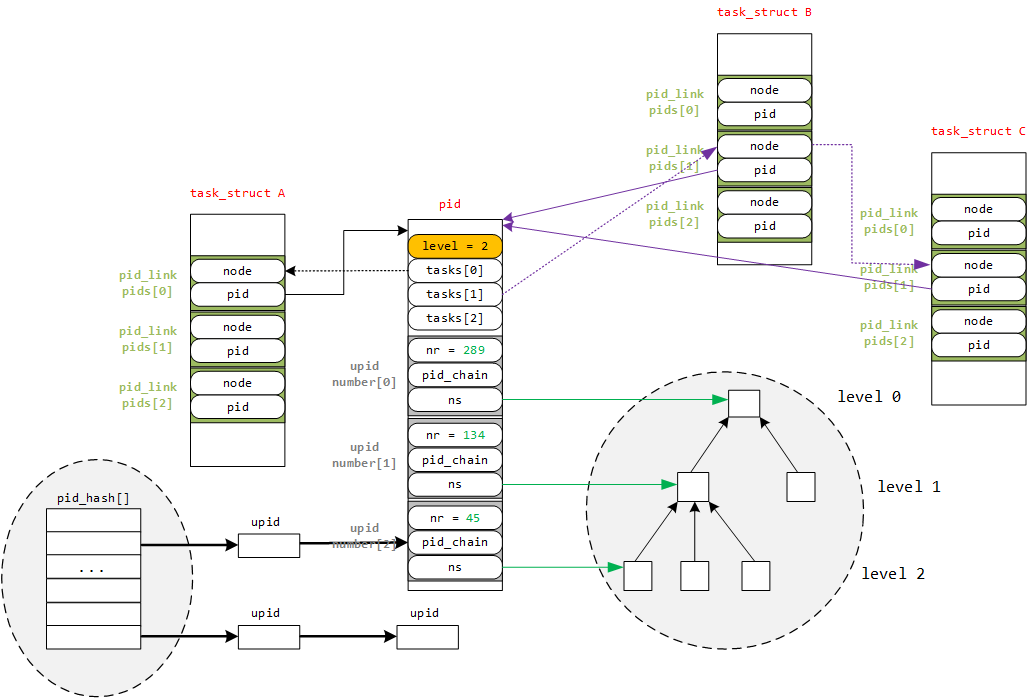
其中进程 A,B,C 是一个进程组的,A 是组长进程,所以 B 和 C 的 task_struct 结构体中的 pid_link 成员的 node 字段就被邻接到进程 A 对应的 struct pid 中的 tasks[1]。 struct upid 通过 pid_hash 和 pid 数值关联了起来,这样就可以通过 pid 数值快速的找到所有命名空间的 upid 结构, numbers 是一个 struct pid 的最后一个成员,利用可变数组来表示这个pid结构当前有多少个命名空间。
0x05 调试实验
Todo
参考资料:
https://blog.csdn.net/zhangyifei216/article/details/49926459
https://carecraft.github.io/basictheory/2017/03/linux-pid-manage/